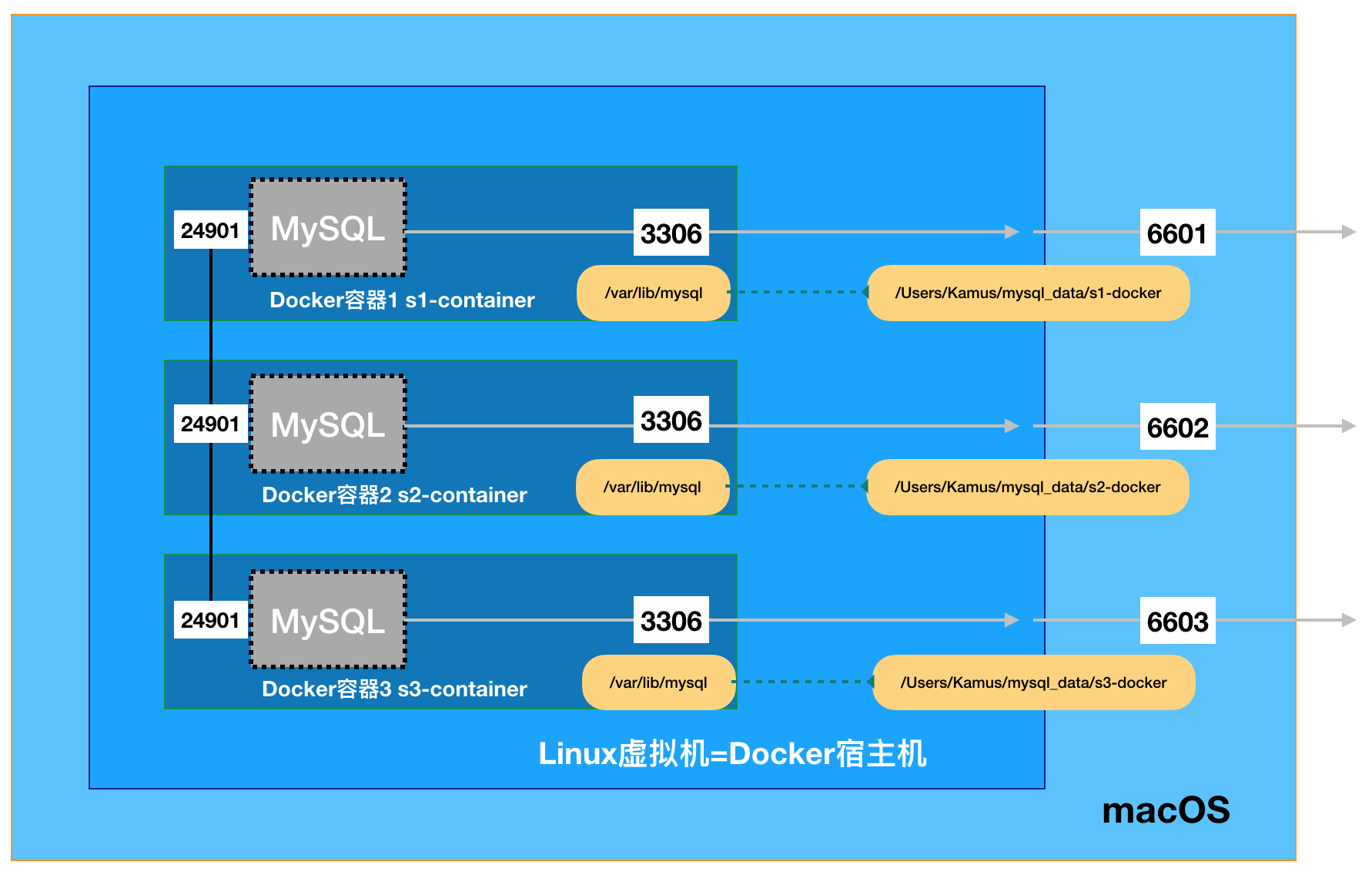
前提条件,已经在自己的macOS操作系统中设置成功了都运行在本地的3节点MySQL Group Replication集群,如何设置,可以参考官方文档中的Deploying Group Replication in Single-Primary Mode。 假设在我们的macOS上已经实现了如下了架构的3节点MGR集群,我们的目标是将这三个数据库全部挪到docker容器中去运行,并且可以互相通信,仍然是MGR集群。 
Docker on macOS
接下来我们把MySQL放在一边,先介绍一下在macOS中的docker架构,在macOS中,docker的实现跟在其它Linux系统中略有不同,在其它Linux系统中,操作系统本身就是docker容器的宿主机,docker镜像都是直接存储在宿主机本身的文件系统中,比如我们通过docker info命令可以看到docker的根目录是:
$ docker info|grep "Docker Root Dir" Docker Root Dir: /var/lib/docker
但是在macOS下,我们直接查看这个目录,其实是根本不存在的。
$ ls /var/lib/docker ls: /var/lib/docker: No such file or directory
Docker宿主机是谁
那么这个目录到底在哪里?实际上是在一个QEMU虚拟机中,当我们在macOS中安装完docker并启动,就是启动了一个虚拟机,这个虚拟机的整个内容全部都在一个文件里,可以在docker程序属性界面中看到这个文件的路径,比如在我的机器上,路径就是/Users/Kamus/Library/Containers/com.docker.docker/Data/com.docker.driver.amd64-linux/Docker.qcow2,该文件通常比较大,特别是安装了多个docker镜像之后,会轻易占用到数十GB的空间。 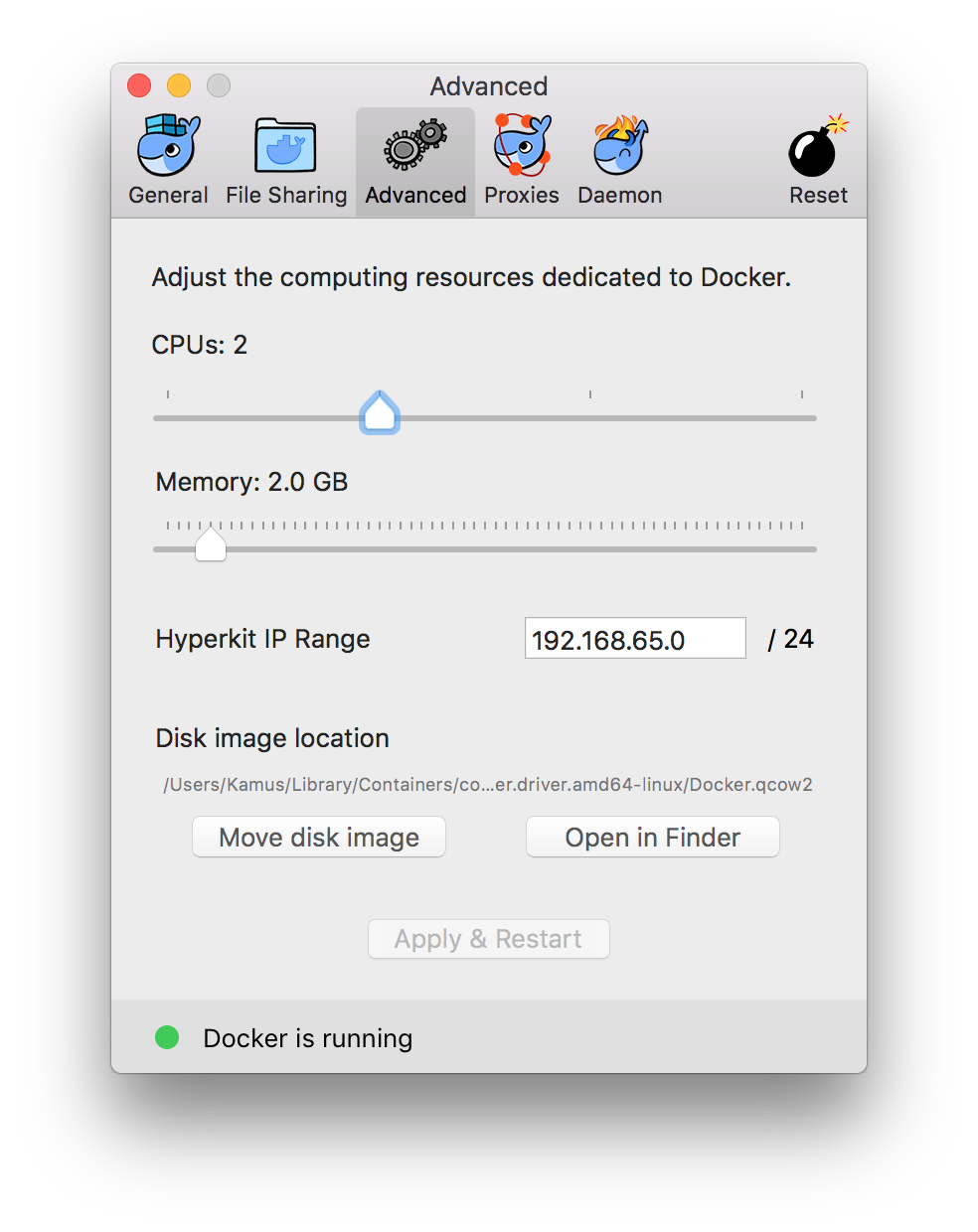 如上图所示,就是Disk image location的位置。 从上图中同样可以看到,这个虚拟机被限制只能使用2颗CPU和2GB内存。 那么,我们是否可以登录这个虚拟机来确认这点呢?使用macOS自带的screen命令可以登录该台虚拟机。如下,可以看到这是一个拥有非常新的Linux 4.9.38版本内核的虚拟机,在这个虚拟机中才有/var/lib/docker目录,只有2颗CPU,总共有2GB内存。
如上图所示,就是Disk image location的位置。 从上图中同样可以看到,这个虚拟机被限制只能使用2颗CPU和2GB内存。 那么,我们是否可以登录这个虚拟机来确认这点呢?使用macOS自带的screen命令可以登录该台虚拟机。如下,可以看到这是一个拥有非常新的Linux 4.9.38版本内核的虚拟机,在这个虚拟机中才有/var/lib/docker目录,只有2颗CPU,总共有2GB内存。
$ screen /Users/Kamus/Library/Containers/com.docker.docker/Data/com.docker.driver.amd64-linux/tty
/ # uname -a
Linux moby 4.9.38-moby #1 SMP Wed Jul 26 10:02:46 UTC 2017 x86_64 Linux
/ # hostname
moby
/ # ls /var/lib/docker
aufs containers network swarm tmp-old volumes builder image plugins tmp trust
/ # cat /proc/cpuinfo|grep "processor"
processor : 0 processor : 1
/ # cat /proc/meminfo |grep "MemTotal"
MemTotal: 2047040 kB
在screen的窗口按组合键control+a d(先按control+a,再按d)可以暂时dettach出这个screen,screen -r可以重新打开窗口。更多的screen命令,可以自行man screen来查看。 所以现在我们可以明确一个概念,macOS本身并不是以后将运行的docker容器的宿主机,而这个Linux虚拟机才是真正的宿主机。这台机器的主机名是moby,这正是docker项目社区版的名称。
Docker宿主机与macOS操作系统的目录共享
由于如下共享文件夹功能的存在,在这个虚拟机中可以访问并更新macOS操作系统本地的目录,这在后面我们将运行在本地的MySQL数据库搬迁到docker容器中起了重要的作用。 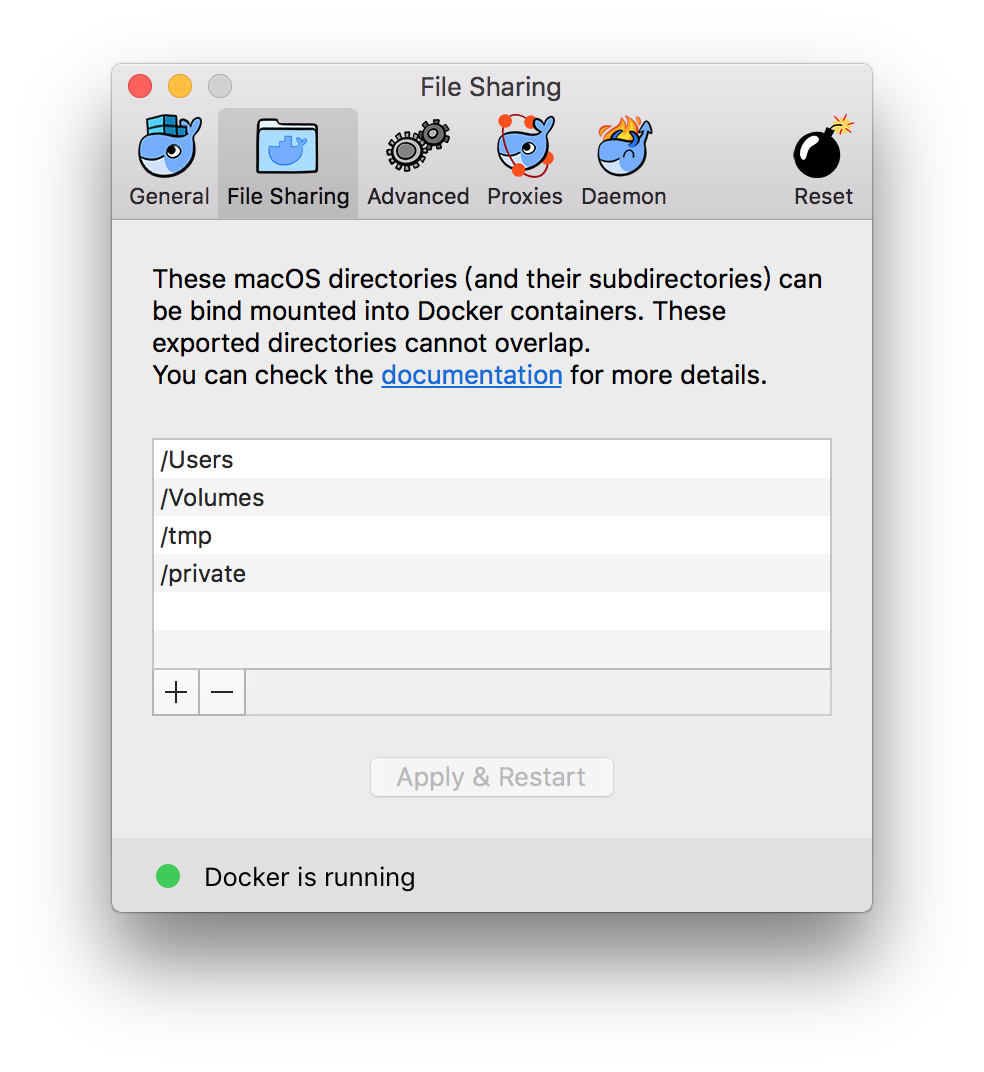 我们还是在screen中看一下这些共享目录的情况。
我们还是在screen中看一下这些共享目录的情况。
/ # df -h|grep osxfs
osxfs 465.1G 324.1G 140.7G 70% private
osxfs 465.1G 324.1G 140.7G 70% /tmp
osxfs 465.1G 324.1G 140.7G 70% /Volumes
osxfs 465.1G 324.1G 140.7G 70% /Users
/ # cd /Users
/Users # ls
Guest Kamus Shared
可以看到,确实macOS操作系统中的目录在虚拟机中是可以直接访问的,而且更方便的地方是,在虚拟机中自动挂载的目录路径跟macOS中的路径是完全相同的,比如我的个人主目录无论是在macOS中还是在这个虚拟机中,都是/Users/Kamus。 那现在我们的思路基本上有了,就是要将原本运行在macOS操作系统中的MySQL数据库的数据文件和配置文件挪到Docker宿主机可以访问的目录下,然后在docker容器中启动MySQL实例。
安装MySQL docker镜像
先要将MySQL docker镜像安装上,这是运行MySQL docker容器的基础。安装镜像极其简单,只需要一步就可以,以下命令在macOS操作系统中执行。 标准步骤是:
$ docker pull mysql
但是由于这样会安装latest版本,而我原先在macOS中的MySQL数据库是5.7.17版本,为了避免可能产生的版本升级问题,我做了指定版本的镜像拉取。
$ docker pull mysql:5.7.17
从官方的docker store中拉取MySQL镜像,大约只需要几分钟时间,完毕以后,可以通过docker images命令来查看。
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql 5.7.17 9546ca122d3a 4 months ago 407MB
store/oracle/database-enterprise 12.1.0.2 f5ffadfccb74 5 months ago 5.27GB
alpine latest 13e1761bf172 15 months ago 4.8MB
hello-world latest 94df4f0ce8a4 15 months ago 967B
第一行就是最新拉取的MySQL镜像,这是创建者在4个月前创建的。
运行MySQL docker容器前的准备
设计docker宿主机目录结构
现在我们已经有了docker镜像,也有了在macOS操作系统中运行良好的MySQL MGR集群,开始迁移。首先当然是干净地关闭在macOS操作系统中的三台MySQL数据库,然后我们设计如下的目录结构,将三个数据库的数据文件全部分别挪进去。
$ mkdir /Users/Kamus/mysql_data
$ mkdir /Users/Kamus/mysql_data/s1-docker
$ mkdir /Users/Kamus/mysql_data/s2-docker
$ mkdir /Users/Kamus/mysql_data/s3-docker
根据之前阐述的共享文件夹功能,可以知道在docker宿主机中是可以通过完全相同的路径访问到这几个目录的,我们将原本在macOS操作系统中的三个数据库的数据文件分别移动到s1-docker,s2-docker,s3-docker目录中,至于哪些文件需要移动,这是MySQL DBA的基本知识,不在这里赘述。 由于目标是能运行MGR集群,那么是有一部分数据库初始化参数要额外设置的,而docker容器中的my.cnf内容无法改动,所以我们再设计一个专门的目录用来存储所有数据库的my.cnf文件。
$ mkdir /Users/Kamus/mysql_data/conf.d
$ mkdir /Users/Kamus/mysql_data/conf.d/s1-docker
$ mkdir /Users/Kamus/mysql_data/conf.d/s2-docker
$ mkdir /Users/Kamus/mysql_data/conf.d/s3-docker
然后将原本各个数据库的my.cnf文件分别拷贝到conf.d/s1-docker等三个目录下,最后形成了如下的目录结构。
$ tree /Users/Kamus/mysql_data/conf.d
/Users/Kamus/mysql_data/conf.d
├── s1-docker
│ └── my.cnf
├── s2-docker
│ └── my.cnf
└── s3-docker
└── my.cnf
3 directories, 3 files
设计这些目录结构的目的是在运行docker容器的时候通过volume选项将数据文件目录挂载成容器内部的/var/lib/mysql目录,将my.cnf参数文件所在目录挂载成容器内部的/etc/mysql/conf.d目录,从而实现MySQL数据库实例启动所需要的所有关键文件都存储在宿主机中,而docker容器本身只提供MySQL软件镜像。这比将所有文件都存储在docker镜像内部更灵活。
设计docker容器主机名和IP地址
在macOS本机运行的MySQL实例中为MGR配置的各种参数中使用到的主机名往往是localhost,IP地址则是127.0.0.1,MGR集群的节点间通信端口也往往是指定了本机IP上的不同端口,如果我们参照了官方文档中的搭建指南,使用的就是24901,24902,24903三个端口。
group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
现在我们既然将数据库搬到了容器中,那么就完全可以重新设计更有意义的主机名和分别的IP地址。 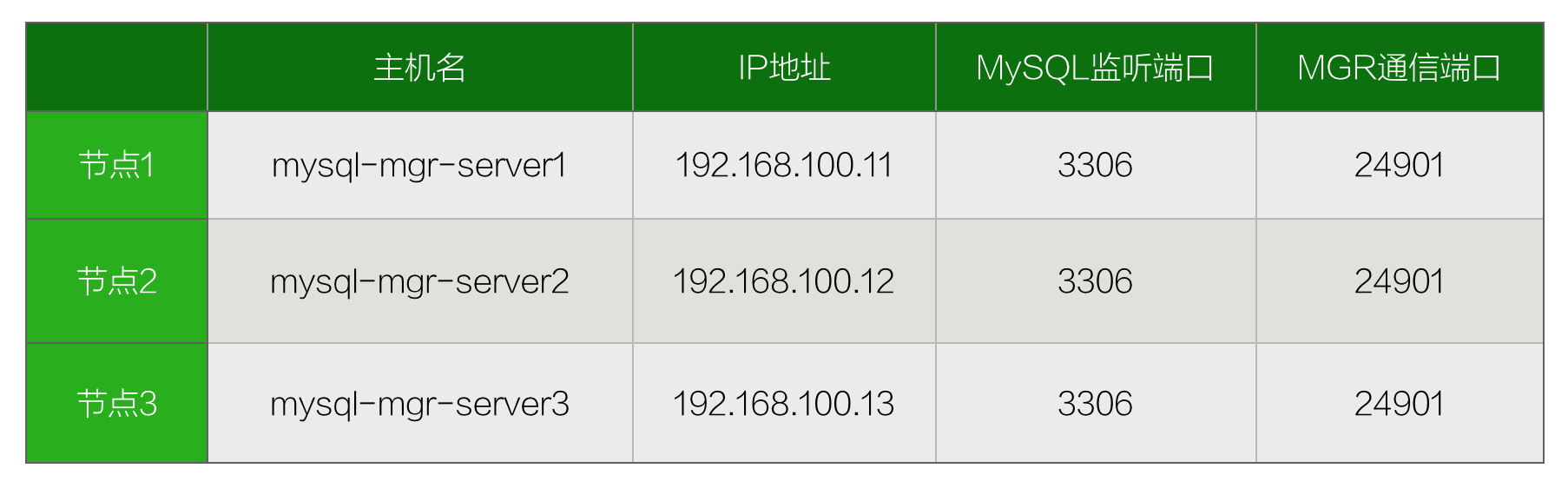 在启动Docker容器的时候,可以通过hostname和ip选项指定主机名和静态IP。可以参照最后运行Docker容器的完整命令。 如果要为Docker容器指定静态IP,则必须要使用手动创建的network,通过以下命令可以创建,比如此处我们创建了名称为mynet的网络。
在启动Docker容器的时候,可以通过hostname和ip选项指定主机名和静态IP。可以参照最后运行Docker容器的完整命令。 如果要为Docker容器指定静态IP,则必须要使用手动创建的network,通过以下命令可以创建,比如此处我们创建了名称为mynet的网络。
$ docker network create --subnet=192.168.100.0/24 mynet
创建完毕以后,通过network ls命令可以查看新创建的网络。可以看到默认是桥接方式。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
45e872bc9b12 bridge bridge local
a1e4739cb508 host host local
9617f8d9b8df mynet bridge local
b0b9d568e2f9 none null local
设计docker容器资源占用限制
对于在同一宿主机上运行多个docker容器,进行资源限制是必不可少的需求,虽然在此文中我们只是进行将MySQL实例搬迁到docker容器中的测试,但是也仍然规划了容器资源限制,由于宿主机本身只有2颗CPU和2GB内存,因此做如下规划。 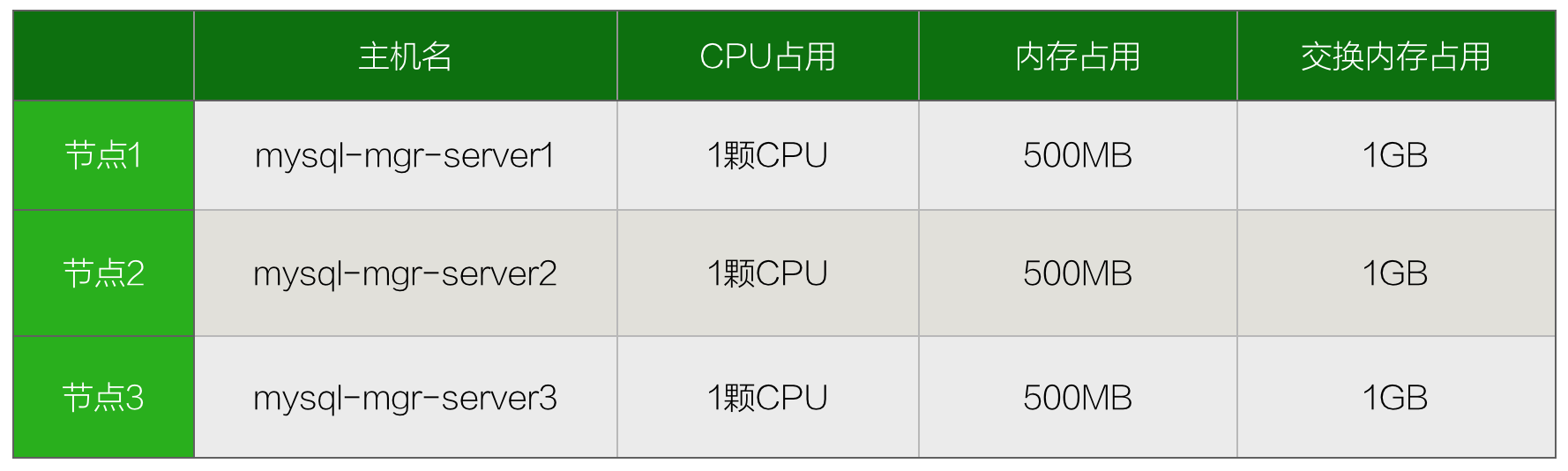 在启动Docker容器的时候,可以通过cpus和memory以及memory-swap选项指定CPU和内存的资源限制。可以参照最后运行Docker容器的完整命令。
在启动Docker容器的时候,可以通过cpus和memory以及memory-swap选项指定CPU和内存的资源限制。可以参照最后运行Docker容器的完整命令。
根据以上设置修改各数据库的my.cnf配置
因为我们设计了容器启动时候会拥有不同的IP地址,因此在容器中运行的MySQL实例的初始化参数中关于MGR的部分也需要指定这些IP地址。以下是my.cnf文件的设置内容。
[mysqld]
# server configuration
datadir=/var/lib/mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port=3306
bind-address=0.0.0.0
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
relay-log=bogon-relay-bin
# Group Replication Settings
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "192.168.100.11:24901"
loose-group_replication_group_seeds= "192.168.100.11:24901,192.168.100.12:24901,192.168.100.13:24901"
loose-group_replication_bootstrap_group= off
三个节点的my.cnf文件内容除了loose-group_replication_local_address参数之外,其它内容都是完全相同的。 对于第一个容器s1-container会使用到的my.cnf文件,这个参数为:
loose-group_replication_local_address= "192.168.100.11:24901"
对于第二个容器s2-container会使用到的my.cnf文件,这个参数为:
loose-group_replication_local_address= "192.168.100.12:24901"
对于第三个容器s3-container会使用到的my.cnf文件,这个参数为:
loose-group_replication_local_address= "192.168.100.13:24901"
运行MySQL docker容器
由于MGR集群要求每个数据库在主机层是可以直接访问到其它节点的主机名的,如果在普通的主机上,只需要修改/etc/hosts文件增加其它节点的主机名和IP地址对应条目即可,但是容器内的/etc/hosts却是无法手动修改的,即使手动增加了条目,只要重新启动容器,该条目就会丢失。 要应对该问题,可以在运行容器时使用add_host选项。在真实的生产环境中,我们可以选择配置专门的DNS服务器来做IP和主机名对应(DNS服务器同样可以是Docker容器,我们后续的测试将增加此部分内容,本文先暂时通过add_host的方式来解决)。 最终运行三个docker容器的完整命令如下:
$ docker run \
--detach \
--name=s1-docker \
--memory=500m --memory-swap=1g \
--cpus=1 \
--hostname=mysql-mgr-server1 \
--net=mynet --ip=192.168.100.11 \
--add-host mysql-mgr-server2:192.168.100.12
--add-host mysql-mgr-server3:192.168.100.13 \
--publish 6601:3306 \
--volume=/Users/Kamus/mysql_data/conf.d/s1-docker:/etc/mysql/conf.d \
--volume=/Users/Kamus/mysql_data/s1-docker:/var/lib/mysql \
mysql:5.7.17
$ docker run \
--detach \
--name=s2-docker \
--memory=500m --memory-swap=1g \
--cpus=1 \
--hostname=mysql-mgr-server2 \
--net=mynet --ip=192.168.100.12 \
--add-host mysql-mgr-server1:192.168.100.11
--add-host mysql-mgr-server3:192.168.100.13 \
--publish 6602:3306 \
--volume=/Users/Kamus/mysql_data/conf.d/s2-docker:/etc/mysql/conf.d \
--volume=/Users/Kamus/mysql_data/s2-docker:/var/lib/mysql \
mysql:5.7.17
$ docker run \
--detach \
--name=s3-docker \
--memory=500m --memory-swap=1g \
--cpus=1 \
--hostname=mysql-mgr-server3 \
--net=mynet --ip=192.168.100.13 \
--add-host mysql-mgr-server2:192.168.100.12 --add-host mysql-mgr-server1:192.168.100.11 \
--publish 6603:3306 \
--volume=/Users/Kamus/mysql_data/conf.d/s3-docker:/etc/mysql/conf.d \
--volume=/Users/Kamus/mysql_data/s3-docker:/var/lib/mysql \
mysql:5.7.17
全部容器都启动完毕以后,可以通过docker ps命令查看容器的运行状态,或者通过docker logs命令查看MySQL数据库日志的输出。非常方便。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2765e9104fe1 mysql:5.7.17 "docker-entrypoint..." 27 hours ago Up 6 seconds 0.0.0.0:6603->3306/tcp s3-docker
1966bea215bc mysql:5.7.17 "docker-entrypoint..." 27 hours ago Up 18 seconds 0.0.0.0:6601->3306/tcp s1-docker
18f68523f3a9 mysql:5.7.17 "docker-entrypoint..." 27 hours ago Up 9 seconds 0.0.0.0:6602->3306/tcp s2-docker
启动MGR
通过如下命令登录到Docker容器的操作系统中,再进入MySQL实例,启动MGR。我们目前设置的是Single Primary模式的MGR,先启动第一个Primary实例。
$ docker exec -it s1-docker /bin/bash
root@mysql-mgr-server1:/# mysql
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.17-log MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
Query OK, 0 rows affected (0.00 sec)
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected (1.07 sec)
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------------+-------------+--------------+ |
CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ | group_replication_applier | 72ad2062-08a3-11e7-a513-5bfce171938d | mysql-mgr-server1 | 3306 | ONLINE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ 1 row in set (0.00 sec)
再依次启动第二个只读实例。
$ docker exec -it s2-docker /bin/bash
root@mysql-mgr-server2:/# mysql
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.17-log MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected (5.60 sec)
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ | group_replication_applier | 72ad2062-08a3-11e7-a513-5bfce171938d | mysql-mgr-server1 | 3306 | ONLINE | | group_replication_applier | 9003e830-08a3-11e7-8ae3-e62d2f6366d2 | mysql-mgr-server2 | 3306 | ONLINE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ 2 rows in set (0.00 sec)
启动第三个只读实例。
$ docker exec -it s3-docker /bin/bash
root@mysql-mgr-server3:/# mysql
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.17-log MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> START GROUP_REPLICATION;
Query OK, 0 rows affected (2.21 sec)
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ | group_replication_applier | 72ad2062-08a3-11e7-a513-5bfce171938d | mysql-mgr-server1 | 3306 | ONLINE | | group_replication_applier | 9003e830-08a3-11e7-8ae3-e62d2f6366d2 | mysql-mgr-server2 | 3306 | ONLINE | | group_replication_applier | 96fe2b5a-08a3-11e7-b383-d7f02f17e847 | mysql-mgr-server3 | 3306 | ONLINE | +---------------------------+--------------------------------------+-------------------+-------------+--------------+ 3 rows in set (0.00 sec)
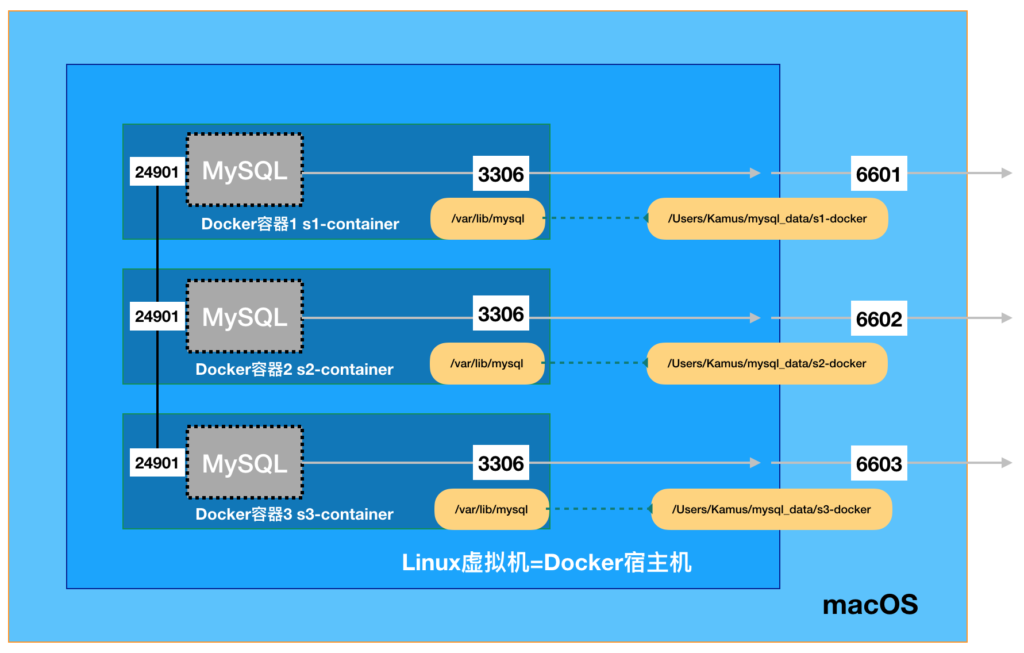
到此为止,我们将原先运行在macOS中的一整套MGR集群全部搬迁到docker容器中。最终实现了如下的系统架构。

 如果要通过远程客户端配置SQL Server,则需要在VPC network的Firewall rules中将1433端口开放,如果是在虚拟机本地的sqlcmd中操作,则无需配置。 操作系统:CentOS7
如果要通过远程客户端配置SQL Server,则需要在VPC network的Firewall rules中将1433端口开放,如果是在虚拟机本地的sqlcmd中操作,则无需配置。 操作系统:CentOS7